Применение трансформеров
Модерация отзывов на сайте с помощью ИИ
(под ИИ имею ввиду модели машинного обученния класса генеративные трансформеры)
Если мы хотим определять нежелательные отзывы (нарушающие наши правила использования сайта) — это задача классификации. Т.е даем модели на входе комментарий (текст) и говорим классифицируй — нарушает правила или нет.
Можно классифицировать по бОльшему числу классов, например «хороший отзыв», «нарушает закон РФ», «содержит мат», «спам»
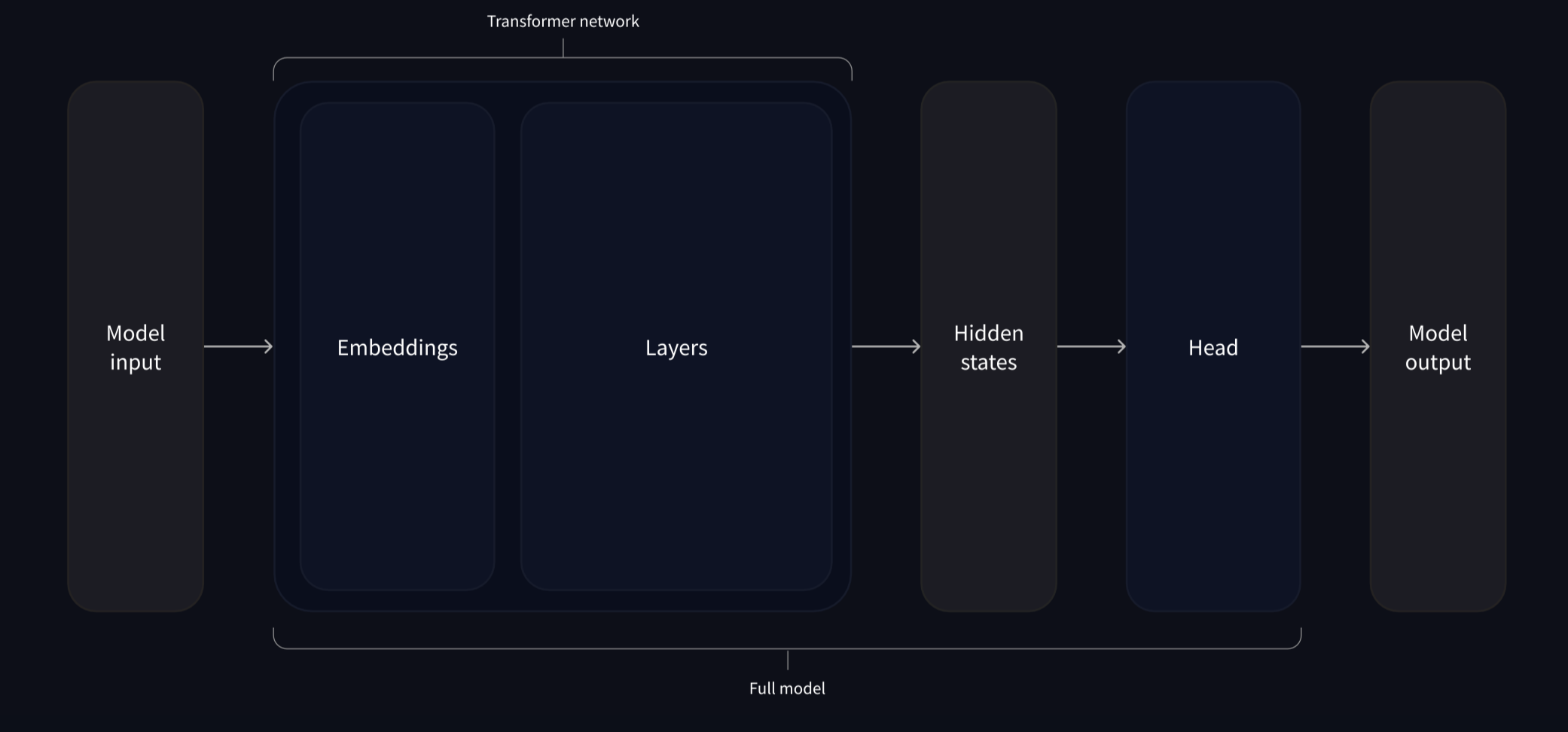
Архитектура модели для такой задачи, верхнеуровнево, состоит из:
- Токенизатора (который превращает текст отзыва в векторное представление — тензор)
- Модели (которая этот тензор классифицирует — говорит к какому классу он принадлежит)
Сама модель, на самом деле, тоже состоит из частей. Опять же верхнеуровнево это:
- Body (тело модели), которое возвращает только признаки (скрытые состояния) — понимание введенного текста в контексте.
- Head — которая уже заточена под определенную задачу, в данном случае классификация.
Головы можно менять. Использовать разные головы под разные задачи, с одной и той же моделью в качестве тела. Кроме этого можно подбирать разные токенизаторы и модели.
Hugging face представляет библиотеку, с которой можно быстро выстраивать такие конвееры, заменяя любую часть пайплайна и находя лучшую для вас комбинацию.
Для задачи модерации пользовательских отзывов на русском языке существует несколько готовых моделей на Hugging Face, которые можно использовать как «голову» (classificationhead) поверх русскоязычных BERT‑моделей. Например:
- s-nlp/russian_toxicity_classifier
- cointegrated/rubert-tiny-toxicity
- Mnwa/modernbert-toxic-russian
- t-bank-ai/response-toxicity-classifier-base
Одна из них от Т-банка, как видите.
Примеры кода
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier(
[
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
)
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
print(outputs.logits)
tensor([[-1.5607, 1.6123],
[ 4.1692, -3.3464]], grad_fn=<AddmmBackward>)
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
tensor([[4.0195e-02, 9.5980e-01],
[9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward>)