Видео: https://youtu.be/eMlx5fFNoYc?si=oRYuO4SOVvxLZv3_
Предыдущие нейронные сети, вроде RNN, анализировали токены анализировались последовательно. Контекст накапливается вдоль цепочки. Проблема была в том, что контекст затухал, чем дальше слово находилось от другого важного слова.
Например башня — это одно слово. Но вот Эйфелева башня уже другое, а если где-то в контексте есть указание, что это миниатюра, это третье значение.
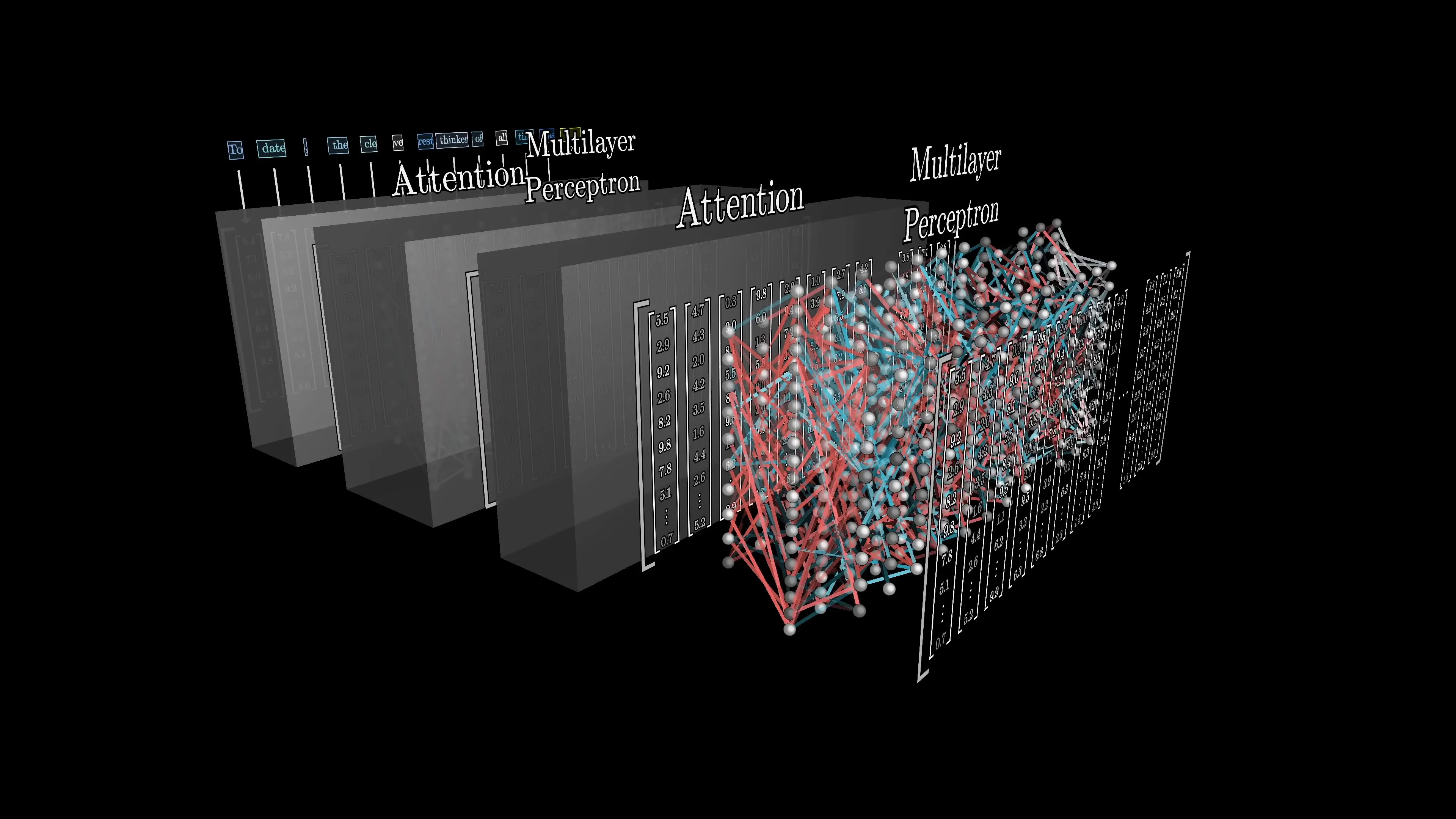
У трансформеров есть механизм Attention, который обновляет эмбеддинг каждого слова в зависимости от всего контекста перед ним.
Работает это путем сверии матричных преобразований.
- На первом этапе для каждого слова (токена) берется эмбеддинг из словаря эмбеддингов.
- Затем формируются вектора для преобразований
- Затем для каждого токена вычисляется вектор вопросов Query — что этот токен «ищет» в других токенах.
- Затем для каждого токена вычисляется вектор ответов на каждый из вопросов Key — как этот токен может быть найден другими
- Затем Value — информация, которую токен предоставляет если его найти
- Затем между всеми парами токенов считается сходство между их запросами и ключами как скальное произведение (нормированное), а результат превращается в распределение вероятностей через softmax, показывающее насколько сильно каждый токен должен «внимать» (Attend to) каждому другому токену.
- Получив веса «Внимания» мы вычисляем новый вектор для каждого токена. По сути это новое представление каждого токена в пространстве смысла, с учетом контекста
Attention(Q, K, V) = softmax(QK^T / √d) * V
То есть каждый токен получает новую «версию себя», в которой учтены все другие токены, но с разным весом важности. Миниатюрная эйфелева башня становится тем, чем она должна быть: игрушкой.

Таких «голов внимания» очень очень много, ведь слова влияют друг на друга разными способами. Описанной мной процесс повторяется много раз. Например в одной итерации Внимание может быть направлено на прилагательные, относящиеся к существительным. Например какого цвета, формы и фактуры вещи в предложении. На другой итерации Внимание может направить на события, произошедшие с вещями.
Например если перед словом Машина написано Попала в ДТП, это окажет сильное влияние на форму и качство машины. А если в тексте со словом Гарри встречается слово Волшебник, вероятно речь идет о Гарри поттере.
Нейросеть производит много итераций внимания вычисляя прибавочный вектор к эмбеддингу каждого токена, пока не получит хороший финальный вариант. GPT-3, к примеру, исплоьзует 93 «Голов внимания» в каждом блоке.
Каждая Голова предлагает свое изменение к вектору каждого токена, уточняя его направление в пространстве смысла.
Так как множество голов обращают внимание на разные аспекты каждого слова параллельно, модель может выучить сразу много способов понимания контекста.