Видео https://youtu.be/wjZofJX0v4M?si=jSsgwvZGGBZXRNQQ
Что такое GPT
Генеративный — генерирующий выходные данные (текст, картинку или аудио) Пред-обученный — обученный на больших объемах данных 🔑 Трансформер — вид модели машинного обучения, архитектура нейросети. Умеет понимать контекст последовательности данных (слов)
🔑 Трансформер — вид модели машинного обучения, архитектура нейросети. Умеет понимать контекст последовательности данных (слов) Внимание — RNN анализировала данные строго по порядку. Трансформер понимает что означает слово на его месте, понимая структуру и смысл языка. Внимание позволяет модели решать, какие слова важны при анализе данного слова.
Как работает Трансформер
Просто: Получает на входе набор данных (текст) и генерирует продолжение. Токен токеном, каждый раз строя распределеине вероятности по всем токенам и выбирая наиболее вероятным.

Подробнее:
- Input. Получает на входе данные (текст, картинку, звук)
- Tokenization. Разделяет на кусочки (токены)
- Attention. Превращает токены в вектора в пространстве высокой размерности (пространстве смысла). Само пространство смыслов и положение каждого токекна в нем определяется как раз на этапе обучения.
- Neural net. Полученные вектора проходят через многослойны перцептрон (Feed forward layer). Интуиция: Это как будто ты задаешь много список вопросов пр окаждый вектор, и записываешь ответ соответствующим весом нового вектора.
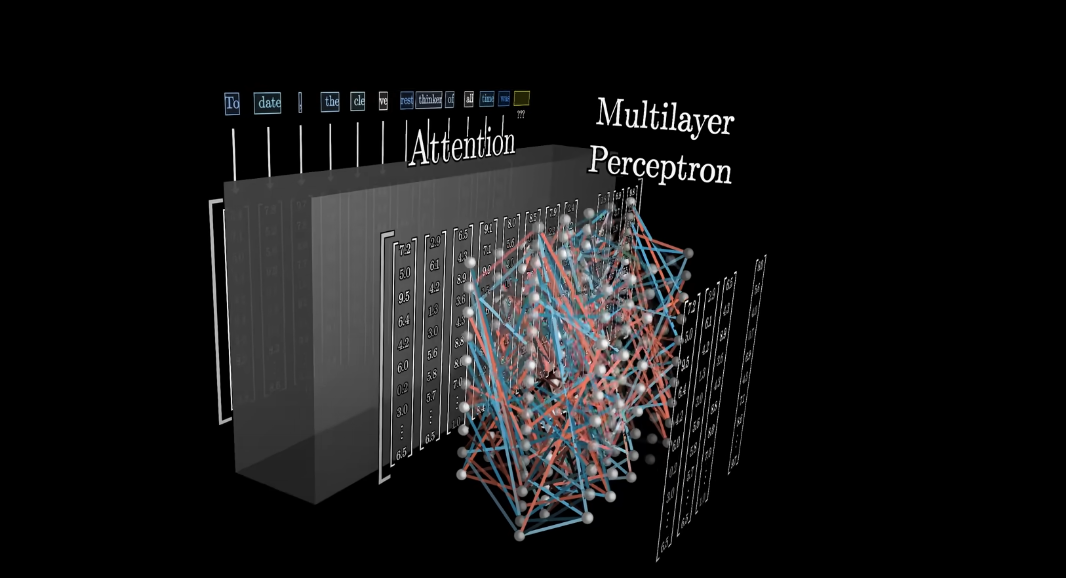

- Repeat. Повторяем предыдущие два шага, до тех пор пока вся предыдущая информация не «впечеться» в один единственный последний вектор. Он и покажет следующий токен.
- Profit. Из всех возможных вариантов продолжения мы только что предсказали, какой единственный должен быть выбран. (Сгенерировали его)
- Repeta2. Повторяем шаги 2-6, пока не сгенерируем текст (картинку, звук) нужной длины.
Токенизация и Пространство смысла
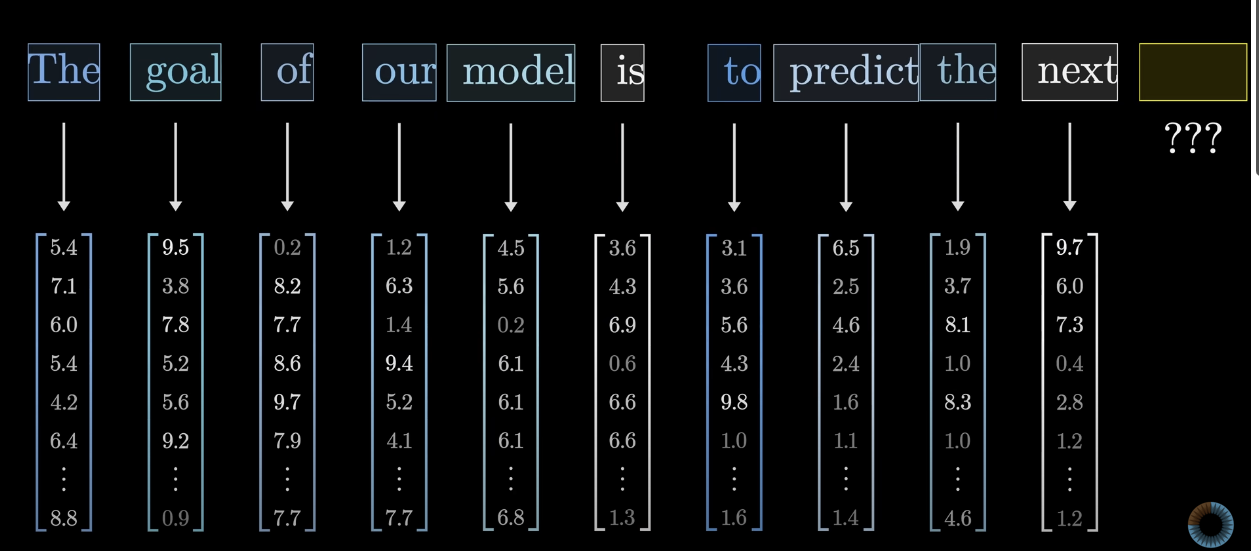
Модель разделяет входящий текст на слова (на самом деле токены — небольшие кусочки текста, удобные со статистической точки зрения. Не морфемы и не слоги, просто кусочки — токены).
Здесь и далее слово «слово» и «токен» я буду использовать как синнонимы. Хотя они не.
Каждому слову заранее известен его вектор в просртранстве смысла. Пространство смысла и вектора уже созданы на этапе обучения модели и представляют собой самую ценную часть технологии. Как они создаются мы здесь не рассматриваем.
Про каждое слово (токен) вектор показывает, сколько «очков» в каждом смысловом направлении получает этот токен. Любопытно, что это позоволяет исследовать пространство смысла визуально.
Например, вектор слова Мужчина отличается от вектора слова Женщина на столько же, насколько различаются вектора слов Король и Королева (почти), а так же Дядя и Тета, Отец и Мать и так далее. То есть одно из направлений в пространстве смысла кодирует гендерную информацию.
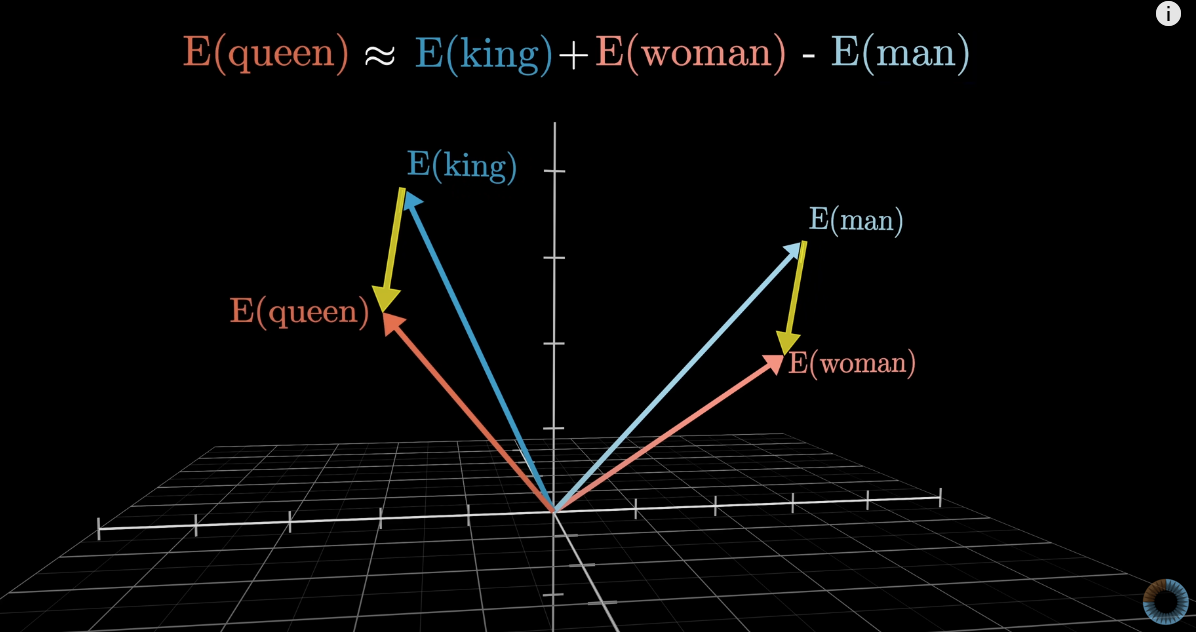
Математически, скалярное произведение (умножение всех соотв. компонентов и сложение результатов) между двумя векторами показывает, насколько хорошо они совпадают по направлению.
Матрица эмбеддингов
Самая соль модели. Пространство смысла, заранее (дорого и долго) выученная, используя огромные корпуса текста. Например модель GPT3 обучена на почти всем объеме текста в интернете.

Размер словаря поделей GPT-2,3.. = 50,257 токенов. Глубина эмбеддингов 12,288. Это число направлений смысла, которые словарь улавливает. При этом словарь состоит не просто из слов, а из слов в конкретном положении в тексте (то есть значение слово в каждом конкретном контексте)
Контекстное окно
За раз сеть может пропустить через себя матрицу огранченного размера. Число векторов называется контекстным окном. Для GPT-3 это 2,048 векторов (токенов). Контекстное окно определяте, как много текста модель может принять во внимание, в процессе генерации следующего слова.
Уточнение смысла слов
- В первом слое вектор каждого слова (токена) во фразе берется из словаря эмбеддингов.
- Проходя через слои сети каждый вектор обогащается с помощью 🔑 Attention и обогощается смыслом, в зависимости от контекста. Понимание каждого слова становится более богатым и специфичным
Например когда модель видит слово Король в тексте, это один вектор. Но потом, анализируя окружающие слова она понимает, что король жил в Шотландии, воцарился убив предшественника и был описан Шекспиром. Это дает более точное понимание о ком идет речь.
Unembedding (Последний слой)
После многочисленных слоев сложения матриц на этапах Attention - Neural net, последний слой должен выдать распределение вероятности по всем токенам, которые могут идти следующими. Наиболее вероятный из них и будет следующим сгенерированным словом.
В нейросетях можно настраивать параметр temperature, которая регулирует насколько большой разброс вероятности допускается при выборе последнего токена, что влияет на креативность результата
Следовательно последний вектор имеет размерность числа слов в словаре (50k) как и вся последняя матрица. Она называется Unembedding matrix.
В распределение вероятностей его превращает функция Softmax. Стандартный способ превратить набор случайных чисел в валидное распределение (все числа должны быть от нуля до единицы, и сумма всех чисел должна быть ноль)